

Fear and Loathing (and Hype and Reality) in Los Angeles
Why the Major Studios Won't Use AI Video Generators Extensively Anytime Soon—And Why That Puts Them in a Bind


For the past 18 months, I’ve been writing about why Generative AI (GenAI) is a disruptive threat to Hollywood. (I laid out the case most recently in this investor presentation.)
The idea is that GenAI will democratize high production-value video creation and exacerbate the low-end disruption of Hollywood that is already underway by creator content.
In this post, I explore another angle: why it will be so hard for the major studios to capitalize on these tools—especially AI video generators like Sora, Veo and Runway Gen-3—themselves.
Tl;dr:
GenAI has many potential applications in the traditional film and TV production process. These include LLMs to assist in scriptwriting; text-to-image generators for concept art or green screen environments; or purpose-built AI tools to automate VFX processes or localization services. But these only are complementary tools for pre- and post-production.
The most potentially transformative tools, in terms of time, labor and cost reductions, are AI video generators that may replace some or all principal photography.
AI video models are advancing at a head spinning pace. In February, OpenAI shocked the industry with its announcement of Sora. Google announced Veo last month and in just the last week or so there has been a spate of similarly impressive next-generation models released or announced, including Kling, Dream Machine and Runway Gen-3.
As impressive as these models are, the studios won’t be able to use them to replace principal photography for a very long time, even if they want to, for three reasons: labor relations, important unresolved legal issues and technical limitations.
With a bad taste still lingering from the WGA and SAG-AFTRA strikes last year and IATSE negotiations underway, anything AI is “third rail” for the studios right now.
If the mantra in Silicon Valley is “move fast and break things,” the mantra in Hollywood is “better run it by legal first.” There are a host of open legal questions about AI, but the most pressing concern copyright infringement and IP rights. For studios, using AI trained on others’ copyrights is a lose-lose: they are either infringing or undermining their own rights.
Despite the amazing quality improvements in these models, they won’t meet the needs of the most demanding directors/showrunners/cinematographers, probably for years. Sora (and Veo, Gen-3, etc.) “don’t know much about history”—or geography or physics or film school. To really replicate cameras, they will require much larger (maybe annotated) training sets, better understanding of physics and much finer-grained control.
The earliest adoption and most important use cases will come outside of the major Hollywood studios. These include empowering the massive creator class and independent producers (who are starting to experiment with animation, horror and sci-fi/fantasy genres), as well as advertising, music videos and educational/corporate/documentary video.
AI won’t replace Hollywood, but the bigger risk is that it disrupts it. Disruption requires two main ingredients: a disruptive innovation that lowers barriers to entry and incumbents who can’t respond. This has both.
Sora Was a Watershed Moment
AI has been used in the TV and film production process for a long time and there are many ways to incorporate GenAI into existing workflows, as I wrote about in AI Use Cases in Hollywood. Many studios are starting to use AI for concept art (storyboards and animatics), localization services (aka “subbing and dubbing”) and post production work, such as automating some visual effects (VFX) or using image generators to replace matte painting (the backgrounds created for use with green screen/blue screen footage). Many writers are probably using large language models (LLMs) to help brainstorm or propose edits, whether they admit it or not.
The most potentially transformative technology, however, is AI video generators, which generate short clips from a text, image or video prompt. As opposed to tools that promise to increase the efficiency of working with film footage, they represent an entirely new way to create video by replacing much, or all, of the principal photography itself. As Runway proudly proclaims: “No lights. No camera. All action.”
As opposed to tools that promise to increase the efficiency of working with film footage, AI video generators represent an entirely new way to create video by replacing much, or all, of the principal photography itself.
AI video generators are improving at an astounding rate and the announcement of OpenAI’s Sora in February was a wake up call for Hollywood (something I wrote about here). Relative to other models, like Runway Gen-2, Pika 1.0, Haiper and Stable Video Diffusion, Sora demos showed radical improvements in:
Temporal coherence/realistic physics (Natural-looking motion from frame-to-frame)
Temporal/character consistency (Objects, color, lighting, people, animals, etc. looking consistent from frame-to-frame)
Length (Sora outputs videos of up to one minute, vs. 18 seconds for models like Gen-2 and Pika 1.0)
In May, Google announced Veo and in the last week or two there have been several competing next-generation models: Kuaishou’s Kling, Luma Labs’ Dream Machine and Runway Gen-3. All have produced very impressive clips, on par or arguably better than Sora.
Here is an amazing clip from Gen-3. Not only is it impossible to tell that this isn’t a person, but notice the realism of how the light changes as the train moves.
It Will be a Long Time Before Hollywood Uses Them Extensively
To be clear, the improvement in many of these tools over the last year has been remarkable and much faster than I expected. As impressive as they are, a very different question is when they might be used extensively in Hollywood.
Even if they wanted to use them, the major studios face three massive impediments: labor relations, unresolved legal issues and technical limitations.
Let’s take them one at a time.
For Studio Labor Relations, AI is “Third Rail”
One of Hollywood’s biggest problems is the complexity of the ecosystem in which it operates.
Talent relations in particular are critical. Studios don’t actually make movies, they need to attract the talent that makes the movies. Plus, the most popular actors and directors often have brands that are more powerful than the studios’ themselves. They can be very vocal and influential in swaying public opinion.
Not many industries have some employees with a higher public profile than the employers themselves.
In last year’s strikes by both the Writers Guild of America (WGA) and Screen Actors Guild - American Federation of Television and Radio Artists (SAG-AFTRA), AI emerged as a key issue. The strikes were ultimately resolved, but some of the ill-will and much of the distrust remains. In addition, the International Alliance of Theatrical Stage Employees’ (IATSE) and Teamsters’ contracts with the studios are set to expire on July 31 and AI is again a key issue in the negotiations.
A few weeks ago, Sony Pictures CEO Tony Vinciquerra stated at a Sony investor meeting that “[w]e’ll be looking at ways to use AI to produce films for theaters and television in more efficient ways, using AI primarily.” The blowback was swift, like this tweet (do we still call them “tweets?”):

As a result, for many studios, anything AI right now is “third rail.”
The Legal Issues are a Quagmire
I haven’t calculated lawyers per employee in Hollywood, but it’s safe to say legal issues are more important in the entertainment business than in many other industries. Hollywood creates copyrighted information goods, which are subject to piracy and infringement and require constant legal vigilance; it traffics in byzantine legal agreements, like talent contracts and licensing and distribution deals; and it’s very high profile, attracting a lot public attention, and, as a result, lawsuits. If the mantra in Silicon Valley is something like Mark Zuckerberg’s “move fast and break things,” the mantra in Hollywood is “you better run it by legal first.”
If the mantra in Silicon Valley is “move fast and break things,” the mantra in Hollywood is “you better run it by legal first.”
The major studios will need very clear legal resolutions before they are willing to extensively use GenAI in principal photography. The two most important issues are:
Copyright Infringement
It is unclear whether training models on copyrighted IP is fair use or infringement.
Fair use is a murky concept that is determined on a case-by-case basis. According to the 1976 U.S. Copyright Act, the considerations that should determine fair use include:
(1) the purpose and character of the use, including whether such use is of a commercial nature or is for nonprofit educational purposes;
(2) the nature of the copyrighted work;
(3) the amount and substantiality of the portion used in relation to the copyrighted work as a whole; and
(4) the effect of the use upon the potential market for or value of the copyrighted work.
For AI video models trained on copyrighted works, the most important are the last two. The argument in favor of fair use is that the models aggregate and “transform” the training data into new content that is not substantially similar (i.e., it doesn’t run afoul of #3). The primary argument against fair use is that the output reduces the value of the copyrighted work (i.e., it runs afoul of #4).
If Veo outputs a video of Batman, that’s pretty clear cut. But if it outputs a moody cityscape reminiscent of Christopher Nolan’s Gotham, is that infringement or not?
As long as this lack of clarity persists, the big challenge for entertainment companies is that using GenAI models trained on other copyright holders’ IP is a lose-lose proposition: either they are infringing on others’ copyrights or they are undermining their own copyrights by implicitly agreeing that training AI models on copyrighted IP is fair use.
For Hollywood, using GenAI models that were trained on copyrighted material is lose-lose legally: either they are infringing others’ copyrights or implicitly undermining their own.
Intellectual Property Rights
A related question is: who owns the rights to content created using GenAI models?
The U.S. Copyright Office has issued guidance that “copyright can protect only material that is the product of human creativity,” meaning a human has to be involved. Other jurisdictions have taken similar views. But how much human involvement is necessary to meet this standard is unclear. Plus, as long as the infringement issue is unresolved, it remains an open question whether the underlying IP used to train the model retains any rights in new model output—or maybe even the creator of the AI model itself.
Video Generators Won’t Replace Principal Photography for a Long Time
In With Sora, AI Video Gets Ready for its Close Up, my subtitle was “Video is a Solvable Problem.” Let me qualify that. Video is a solvable problem in that it is increasingly obvious that these tools will enable very high quality, coherent video that will be more than good enough to tell a compelling story. But they still fall short of what talent will require to replace significant portions of principal photography. They probably will for some time.
To understand why, it helps to have a high-level understanding of how GenAI models works generally and their resulting technical advantages and limitations. I try to provide that in the Appendix.
The basic idea is that all GenAI models (whether text, audio, image, video or any other digital modality you can imagine) are trained by ingesting vast amounts of data. They represent that data mathematically and run it through neural networks to understand specific characteristics of the data and the relationships and patterns within it. When fed a prompt, they analyze the prompt and then draw from their understanding of their training data to probabilistically determine the best output.
All GenAI models—whether transformers, diffusion models, General Adversarial Networks (GANs), or whatever—have certain limitations.
As a result, all GenAI models have inherent advantages over humans: cost; speed; volume of knowledge; the ability to create many iterations; and the ability to make unexpected connections.
But they have a lot of limitations too:
they are only as good as their underlying training sets;
they have can create false, inconsistent or just weird output (hallucinations) because they have no understanding of what their data represents, and are only “stochastic parrots”;
everything they know is derived from digital data and, since they have no physical embodiment, they do not understand the physical world;
they lack emotion and, therefore, taste;
they are sub-symbolic systems, so—just like looking into someone’s brain wouldn’t help you understand what they’re thinking—there is limited transparency into how they produce output;
and, with little transparency into how they work, it follows that it is difficult to exert precise control over their output.
AI video generators suffer from all these problems, to varying degrees, but here are some of the biggest limitations for professional creators.
Limited Training Sets
As described in the Appendix, state of the art LLMs (GPT-4o, Google Gemini Ultra, Claude Opus, etc.) have been trained on virtually all the scrapable text on the Internet. By contrast, most high-quality video footage is not accessible. Or, for the reasons I described above, at least not with legal clarity.
Most professionally-produced film and TV footage is locked in the libraries of Warner Bros., Disney, NBC Universal, Sony and Paramount, all of which have thousands of movies and tens of thousands (and sometimes hundreds of thousands) of TV episodes. According to Bloomberg, Alphabet and Meta are currently in discussions to license some of this content, but it isn’t clear what rights they’ll get, if any. (Also, a significant proportion of this film has never been digitized.) Similarly, these models don’t yet have access to professional sports footage.
This limited training set leads to several other drawbacks.
Sora don’t know much about History—or Physics or Geography or Film School.
Sorry, They Don’t “Understand Physics” Yet
When OpenAI announced Sora, it posted a really cool clip of two pirate ships battling each other in a cup of coffee, shown above. How could it create something that never occurred?
It prompted some to breathlessly proclaim that Sora was a “world model” that had inferred from visual data a holistic understanding of the physical world. This is unlikely. While the clip is an incredible achievement, it is far more likely that it is created through “combinatorial generalization”—the combination of Sora’s knowledge of pirate ships, coffee cups and fluid dynamics—not a world model. Runway is actively working to create General World Models and calls Gen-3 a step in that direction. Nevertheless, this will take a while and many believe that to do so in a comprehensive way will require some sort of physical embodiment.
At the risk of indicting all the latest generation of models from just one render, below is my test of Dream Machine’s knowledge of physics. I gave it a very challenging prompt: “an overhead shot of a man playing pool and breaking a rack of balls.” As shown, it knows what pool is, but it has no understanding of Newtonian mechanics or, for that matter, cause and effect. (Or “overhead.”) It also seems to think that a pool cue is able to emerge out of a table.
In theory, an AI-generation tool could combine a model trained on extensive video footage with a physics simulation (either by building its own or partnering with a company like Epic, which has a physics engine within the Unreal Engine (UE)), but who knows the technical complexity of this type of integration. Also, while the UE physics engine is very advanced and can simulate a lot of the physical world, it is mostly geared to creating realistic games and other virtual experiences. It too is not a true “world model.”
They Don’t Know History or Geography Either
For similar reasons, they don’t have deep training data on different geographies or time periods. If someone wants to make a historically-accurate film set in 1920s Paris, for instance, today these models will struggle.
I apologize for picking on Dream Machine again, but Sora, Veo and Gen-3 aren’t publicly available yet. Below is the first (and only) render from my prompt for “a car chase in 1950s-era New York City.” Ignoring the weird physics for a moment, note that these cars are probably circa late ‘30s-early ‘40s. Also, that big building on the right sure doesn’t look like something that would’ve been standing in 1950.
They’ve Only Taken Film 101
Over the last year, AI video generators have been adding more creator control, something I discussed in Is GenAI a Sustaining or Disruptive Innovation in Hollywood?
Runway Gen-2 is the best example. On release, it was essentially a slot machine, in which the creator entered a prompt, “pulled the handle,” and held her breath during the render time to see what popped out. Since then, Runway has increased control by enabling creators to upload a reference image and added Camera Control (sliders that enable pan, zoom, tilt and roll) and Motion Brush (which allows users to specify which elements of a video should move). (Figure 1 shows an example of Motion Brush.)
Figure 1. An Example of Runway Gen-2 Motion Brush
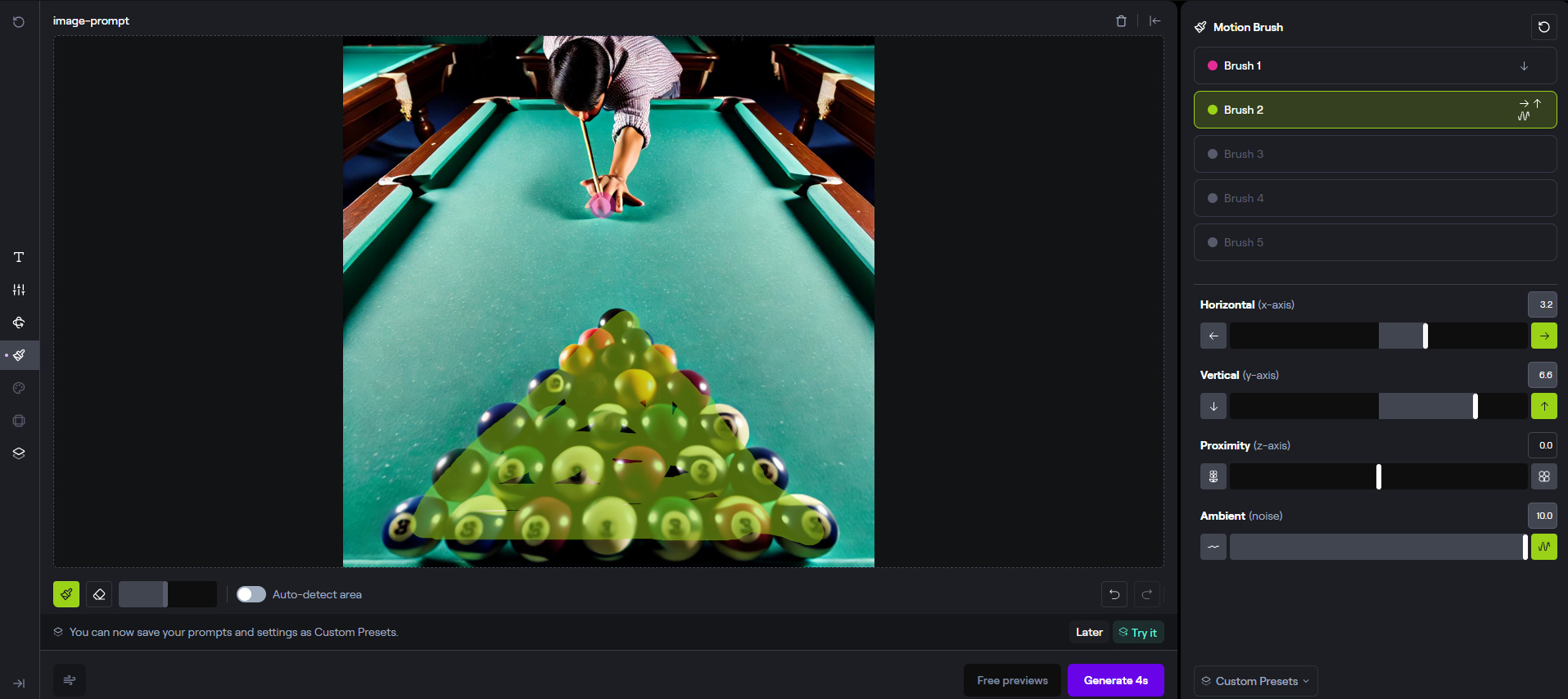
With its announcement of Gen-3, Runway has also promised more tools for finer-grained control of “structure, style and motion.” But these will likely fall far short of what an experienced director or cinematographer/director of photography (DP) would want or expect.
Suppose a DP says, “Ok, I want to use a Panavision Millennium DXL2 with a 35mm lens and Fuji Eterna 500 ISO film stock. Here’s my shot list. Shot 1: Dolly in from wide shot to medium shot. Shot 2: Handheld, following character…” Even the most advanced models today have a limited understanding of what this means.
There are two paths to finer-grained control, which could be used together. Both are challenging:
Extensive annotation of existing film catalogs. One approach would be to offer more control on the front end, by accommodating highly technical prompts. In theory, this would be possible by training on very large datasets that have been annotated with information about camera angles, lenses, film stock, lighting and other technical details—essentially, sending Sora to film school.
As mentioned, several video models are reportedly trying to license training data from Hollywood. But the annotation process would be difficult. Generally, films and TV shows have shot lists and detailed production notes, but: a) who knows if studios keep them; b) even if they have, it is extremely unlikely that these have been converted to metadata associated with footage; and c) in many cases, the actual shots differ from what was initially planned. Annotation might be possible with some sort of auto-generation tool, but it probably would require a large number of experts examining and manually annotating footage.
Perhaps a CAPTCHA used only at film schools?
Manipulation in the latest space. The other approach is to make the generation process more interactive by enabling users to “condition” the output by manipulating the latent space.
As described in the Appendix, the latent space is a distilled representation of the training and output data. For instance, let’s say that that a diffusion transformer model like Veo comprises tokens (which represent small patches of video) and each token has 1,024 dimensions (where each dimension has a value between -1 and 1). The latent space representation of these tokens might have, say, 1/10 as many dimensions—small enough to be more efficient, but large enough to capture the key attributes of the token.
Manipulation in the latent space is a little like tweaking what someone is thinking by adjusting which neurons fire—very hard to do with precision.
From its training data, the model may learn the latent dimensions associated with visual concepts, like brightness, color saturation, motion blur, camera distance, etc. Tools like Motion Brush work by allowing users to change these latent dimensions. It’s a little like tweaking what someone is thinking by changing which neurons fire.
In theory, these kind of controls could extend beyond simple camera motions to a wider range of shots and the ability to control the intensity and source(s) of light, film stock, camera lenses, etc. However, this would also require a sufficiently extensive training set. In addition, this approach is very complex because discrete dimensions don’t map to specific visual elements 1:1; multiple dimensions are associated with different visual elements. So, it can be both difficult to disentangle which dimensions are associated with which visual attributes and altering them can have unintended consequences.
The Most Promising Near-Term Use Cases Are Outside Hollywood
For all these reasons, it will be a very long time before a major studio releases a film that is largely or entirely created with AI.
What are AI video generators good for then? A lot. They will be most effective for use cases that work within their constraints or even exploit them. This includes basically everyone with lower production-value standards than big budget Hollywood series and movies:
Creator Video
At the heart of it, GenAI tools democratize information creation. As I’ve written many times (like Forget Peak TV, Here Comes Infinite TV, How Will the “Disruption” of Hollywood Play Out?, Is GenAI a Sustaining or Disruptive Innovation in Hollywood? and most recently GenAI in Hollywood: Threat or Opportunity?), I think the most important and impactful use case is empowering the vast number of creators who would love to tell compelling stories using video, but who would never even consider doing a physical shoot and painstaking post production work. Relative to the cost and practical inaccessibility of traditional shoots, these kinds of creators will probably be happy to cycle through many iterations of each shot and live with the inconsistencies and imperfections that crop up.
While the models are advancing fast, the workflows will get more accessible for individual creators too. Platforms like LTX Studio and Lore Machine aim to make it easy to go from prompt to finished film. It seems likely that these sorts of user-friendly creation/editing features will eventually be included in TikTok and YouTube Studio — and that basic editing products like CapCut and Premiere Rush will also include more GenAI features. (These may use their own native models or integrate with third-party models via API calls.)
The most impactful use case will be empowering creators outside of Hollywood.
Independent Producers/Small Professional Teams
I also think that there are a lot of teams of independent Hollywood professionals that would be eager to unshackle themselves from the studio system and end their fealty to studio checkbooks.
Animation, horror and sci-fi/fantasy are the most obvious genres to incorporate some AI video first.
That’s especially true for any genre that isn’t reliant on highly emotive human actors. (Good rule of thumb: if Meryl Streep could be in it, it’s probably not the most fertile ground.) Animation is the lowest-hanging fruit for the obvious reason. Horror might also benefit from the surreal and unsettling nature of a lot of AI-generated video. Sci-fi/fantasy are already often VFX-heavy and, in many cases, don’t rely heavily on human faces.
Advertising
This topic is an entire post in itself. Big brands’ may use GenAI to create ads that would’ve been prohibitively expensive with traditional VFX, like this cool ad from Coca-Cola. In house teams will likely use video generation tools to quickly iterate through a lot of creative ideas before turning them over to agencies or even produce some of their creative entirely themselves. GenAI will also make it much more feasible to run multiple versions of ads for A/B testing. SMEs, for which video production was prohibitively expensive, may see AI video generators as an opportunity to expand their media mix.
Music Videos
Music videos are often highly stylized and don't require strict realism. The surreal, abstract nature of a lot of AI video generation, which is a liability in traditional filmmaking, may instead complement the music.
For instance, check out this video by Paul Trillo, which uses Sora to create what looks like a series of improbably-long tracking shots, or what Trillo calls “infinite zoom.” Also consider the literally millions of independent musicians (Spotify has 10 million artists who have uploaded at least one track) who previously wouldn’t think of making a music video.
Educational/Documentary/Corporate
For educational and documentary content and all those horrible corporate training/compliance videos, AI video generation could be a much faster and cheaper path. While historical accuracy may be a challenge for the same reasons I cited above, these tools can still be effective for illustrating concepts, processes or how not to run afoul of HR.
They Will Work Their Way Into Traditional Production Processes, But at the Periphery For Now
Once Hollywood gets sufficient comfort with the unresolved legal questions and talent (slowly, reluctantly, inevitably?) adapts to the concept of AI as a tool, AI video generators will likely start to be woven into traditional production processes. Here are some use cases that are feasible today:
Previs. Previs, or previsualization, is the process of creating rough visual representations of scenes before filming. Today, tremendous amounts of time are spent just setting up cameras and lighting equipment and checking shooting conditions, even before actors step on set. And then directors or DPs may change their minds once they see the planned shots in action, requiring time-consuming (and costly) changes. More detailed and realistic previs could save a lot of shooting time by reducing the time to setup and the need for on-set changes and retakes.
Establishing shots/B-roll. Establishing shots and B-roll are used to give context to a scene. AI-generated establishing shots could be much cheaper than going on location and, with some manual touchups, they could easily be integrated with live-action footage.
Interpolations/extensions of footage and digital reshoots. AI video generation could potentially be used to interpolate between frames to create slow-motion effects, extend footage, or even do digital reshoots (i.e., not requiring actors to come back on set). By using existing footage as a reference input, the AI could generate new frames that match the original style and content.
Replace and Disrupt are Different
There is a lot of confusion in Hollywood about what all this means. Consider the following two quotes, which occurred just a couple of weeks apart.
In a recent NY Times interview, Netflix Co-CEO Ted Sarandos said:
Writers, directors, editors will use A.I. as a tool to do their jobs better and to do things more efficiently and more effectively. And in the best case, to put things onscreen that would be impossible to do…A.I. is not going to take your job. The person who uses A.I. well might take your job.
Here is Ashton Kutcher talking about Sora, two weeks later:
[Eventually] you’ll just come up with an idea for a movie, then it will write the script, then you’ll input the script into the video generator and it will generate the movie. Instead of watching some movie that somebody else came up with, I can just generate and then watch my own movie…What’s going to happen is there is going to be more content than there are eyeballs on the planet to consume it. So any one piece of content is only going to be as valuable as you can get people to consume it. And so, thus the catalyzing ‘water cooler’ version of something being good, the bar is going to have to go way up, because why are you going to watch my movie when you could just watch your own movie?
These seem to be mutually incompatible statements, but they’re not. They illustrate the distinction between replace and disrupt.
Sarandos was being diplomatic. AI is certainly on a path to make TV and film production more efficient and some of those efficiencies will come in the form of reduced need for labor (in the form of smaller crews, fewer shooting days or both). But, broadly, he is saying that AI won’t replace Hollywood anytime soon. For the reasons I cited above, I think he’s right.
Unfortunately for Hollywood, Kutcher is right too. He is essentially saying that GenAI, and AI video generators in particular, will disrupt Hollywood by lowering the barriers to entry to make high-production value video.
I’ve heard to counterpoint: most of that stuff will stink. I agree that the vast (vast, vast) majority will be unwatchable, but the math is still overwhelming. Hollywood produced 15,000 hours of fresh TV and films last year, while creators uploaded ~300 million hours to YouTube. If even a tiny proportion of that is considered good enough to compete for viewers’ time and attention, it could radically change the supply/demand dynamic for professionally-produced video content. And, for the same reasons that AI won’t replace Hollywood, it will be very hard for the major studios to capitalize on these tools themselves.
AI may not replace a lot of jobs in Hollywood, but the bigger problem is that it could make Hollywood a smaller business.
Should most people in Hollywood be worried that AI will take their job anytime soon? No. But they should be worried that more competition will ultimately make Hollywood a smaller business. AI does not need to replace Hollywood to be disruptive; it just needs to reduce demand for what Hollywood makes.
Appendix
How GenAI Works
If you are conversant in TensorFlow or PyTorch, you can stop here. But to understand GenAI’s inherent advantages and limitations, it’s helpful to first understand how these models work, at least at a high level.
There are many different types of GenAI models, such as transformer models (a type of autoregressive model, meaning it predicts the next element in a sequence), diffusion models (which generate output by transforming random noise into something coherent) and GANs (which pit two neural networks against each other to produce the best output). Today, many AI applications employ several of these models. For instance, Sora and Veo are transformer diffusion models and Midjourney (probably) uses both transformer and GAN models.
Rather that discuss the differences, let’s walk through the commonalities among them:
They are trained on a vast “corpus” of data. GenAI models ingest a vast amount of training data (words, images, audio, video), which they represent in some mathematical way (called “embedding”). For instance, in the pre-training phase, a LLM will break all the input text into tokens (words and parts of words) and then assign each token a multi-dimensional vector value, essentially placing the token in multi-dimensional space. (GPT-4 has reportedly been trained on 10 trillion words, broken into 13 trillion tokens, and each token has been assigned a vector value with 4,096 dimensions.) Figure A1 shows this conceptually, although with only three dimensions. (Close your eyes and imagine 4,096 dimensions - it’s easy!) In some models, this representation is then distilled into a “lower dimensional latent space,” meaning fewer dimensions that are meant to represent its key attributes. That will be relevant shortly.
Figure A1. A Simple Illustration of an LLM Embedding Space

Source: Stack Overflow.
They learn patterns and relationships from the training set. All this data is then fed through a neural network to better understand the data and the structures, patterns and relationships within it. The basic idea is that all neural networks consist of an input layer, some number of hidden layers and an output layer. Each hidden layer analyzes and identifies increasingly complex elements of the input, passing on information to the next layer, finally culminating in an output.1
During the training process, the quality of this output is evaluated and weights and other parameters in the model are continuously adjusted to improve the performance (“minimize the loss function”). This training may be supervised (i.e., humans evaluate the output), unsupervised (it learns relationships from the data itself, such as the way that a transformer model learns the semantic relationships between tokens based on how they appear together in sentences) or a combination (semi-supervised). As mentioned, the mathematical representations (embeddings) of the data also reflect the relationships within them. This can be seen by looking again at Figure A1. Note that “wolf” and “dog” are close to each other in vector space, as are “banana” and “apple.”
The generate output from a prompt. Once the model has been adequately trained, it is ready to be deployed and start generating output. Most support “conditional generation,” meaning that they generate output based on an input, like a text prompt in ChatGPT or Midjourney or a reference image in Runway Gen-2.
They do this by subjecting the prompt to a similar process that they did the training data, first embedding it as a mathematical representation. In some cases, they also then convert this embedding into a “latent representation.” Then, the representation is processed through the model to better understand it and how to generate appropriate output.
This output is determined probabilistically. For instance, an LLM works by predicting the next token in the string, which is based on a probability distribution across its entire vocabulary of tokens. As much as it seems like ChatGPT understands you, it has no idea what it’s saying. It is just string of probabilistically-likely words.
They generalize. By learning the key attributes of their training data, they are able to generate novel samples that have the same attributes, but differ in the details (e.g., generate a never-before seen picture of a cat, new reggae song or new haiku).
They purposefully introduce variability. Most use stochastic sampling techniques or introduce random noise to ensure there is variability in output, even from identical prompts.
GenAI Advantages and Limitations
With a cursory understanding of how they work, we can start to sketch out the relative inherent advantages and disadvantages of current GenAI models relative to the alternative, humans:
Advantages
Speed. They are, obviously, almost immeasurably fast relative to people at both ingesting information and producing output.
Iteration. Due to their speed, they can produce vastly more iterations than people can unaided.
Volume of “knowledge.” This can be an advantage or disadvantage, depending on the modality. GenAI models are only as good as their training data, and some modalities have more accessible data than others. State of the art LLMs, for instance, have scraped almost all the text on the internet. For text, the knowledge base of LLMs exceeds that of humans by orders of magnitude.
Unexpected combinations. These models aren’t “creative” in the way humans are. Their “creativity” is a function of the patterns they’ve divined from their training sets and the degree to which the model purposely introduces variability in its responses. So, while I certainly wouldn’t argue they are more creative than people, owing to the volume of their training information and the systematic and comprehensive way they analyze patterns, they can recognize unexpected connections and create unexpected combinations.
Limitations
Hallucinations. GenAI models sometimes generate output that is nonsensical or just factually wrong. That’s because they rely on patterns, not a true understanding of the information, and simply produce the probabilistically best output. (They are just “stochastic parrots,” as coined in a now-famous paper.) In the case of a LLM, this may mean making up facts or being internally inconsistent. For image or video models, they often produce output this is weird or physically impossible.
Hallucinations continue to improve with each generation of models, which are being trained on ever-larger datasets and have more parameters. It has been shown that loss rates, a measure of model accuracy, improve as compute, dataset size and the number of parameters increase. Further improving model accuracy is an active areas of research, especially for LLMs.2
Figure A2. Scale Improves Model Performance
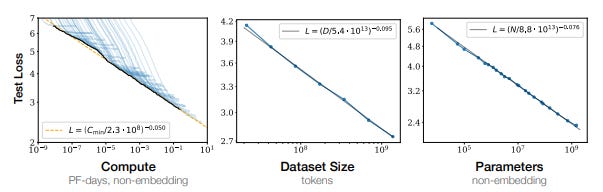
Source: Scaling Laws for Neural Language Models.
Only as good as the training set. As I wrote above, they are only as good as the underlying training set. For video models in particular, the training set is far more limited than text.
Limited or no understanding of the natural world. GenAI models have no physical embodiment, so everything they know about the physical world is inferred from digital data. They often struggle with tasks or prompts that require a deep understanding of physics, causality or real-world constraints. As mentioned above, there are ongoing efforts to create “world models” by training on extensive video data and possibly some sort of physical presence, but that is only an area of research right now.
Lack of emotion and, therefore, taste. I don’t know if this is a controversial view, but in my opinion, what makes art “art” is its ability to evoke an emotional response. GenAI models may understand the semantic relationships between tokens and they may simulate emotion based on their training data, but they obviously feel no emotion. A human can use GenAI tools to create something that evokes an emotional response—yes, “art”—but the model itself won’t understand why or how it did.
Lack of transparency into the generation process. If you could see into someone’s brain, you wouldn’t be able to tell what they were thinking (to do that, you need to fall into a tub with your hair dryer, like Mel Gibson). Likewise, if you could see all the weights and activation values in a neural network it would be meaningless. This lack of transparency—or “interpretability”—can make it difficult to audit, debug, or explain the model's behavior, which is important for accountability and trust, especially for high-value uses. There are areas of research here too, but consider that the human thought process is still shrouded in mystery three decades after the invention of frequency magnetic resonance imaging (fMRI), which enables researchers to see what areas of the brain are activated during different tasks. It isn’t clear to what degree it will be possible to ever understand specifically how these models produce an output.
Lack of fine-grained control. If it is hard to understand the generation process, it follows that it is tough to precisely control it. Current GenAI models allow for some degree of control through prompt engineering and, in some cases, direct manipulation in the latent space, but it’s far from precise.
Legal and ethical concerns. This is an entire post in itself, but obviously GenAI has many unresolved legal and ethical questions that follow directly from their underlying technology. These include questions about the provenance of the data used to train models (and when using that data infringes on copyrights), intellectual property (IP) rights of AI-generated work and the potential for misuse (such as purposely using GenAI to violate copyrights or generate harmful misinformation).
To make this more tangible, in an image recognition model, each hidden layer consists of multiple neurons (or nodes, since they function quite differently than biological neurons), each of which is mapped to a section of the image and all of which are looking for specific features. For instance, the first hidden layer may be looking for vertical edges, the second hidden layer horizontal edges, etc.
This includes new architectures and training methods, as well as techniques to augment or guide model output, like Buffer of Thought (BoT), which compares LLM output to a library of known information; and RAG (retrieval augmented generation), which is similar, but feeds relevant information into the model prior to generation to guide the output.
Ashton Kutcher hit the nail on the head. The end result is why would I ever watch your movie when I can watch my movie. Question is how do I get you to watch my movie? I’ll have to pay for your attention. In the end we will still love those Hollywood classics and actually value them more because it took thousands of real folks to create the final product.
Best piece I've read on the current situation. Hollywood is in a bind. It will require real courage and business savvy to differentiate their offering in a sustainable way. We'll see.
And "sending Sora to film school" is a great pull quote that will stick with me. I will be repeating this in conversation!