



With Sora, AI Video Gets Ready for its Close Up
Video is a Solvable Problem


In December 2022, I wrote The Four Horsemen of the TV Apocalypse. It argued that GenAI, among other technologies, could prove disruptive to Hollywood by blurring the quality distinction between independent/creator content and professionally produced content “over the next 5–10 years, resulting in ‘infinite’ quality video content.” (For more about this topic, see How Will the “Disruption” of Hollywood Play Out?, AI Use Cases in Hollywood and Is GenAI a Sustaining or Disruptive Innovation in Hollywood?)
A year ago, this was an abstraction and a theory. With OpenAI’s release of Sora last week, all of a sudden it is a lot less theoretical. It also seems like “5-10 years” was an overestimation. Things are moving wicked fast.
In this post, I discuss why Sora is such a big deal and what’s at stake.
Tl;dr:
When discussing the potential for AI to disrupt Hollywood, it’s important to be clear what both disrupt and AI mean.
By disrupt, I mean Clay Christensen’s low-end disruption, which provides a precise framework to explore how it might occur and the implications.
All “AI” is not the same. Some AI tools are being used as sustaining innovations to improve the efficiency of existing workflows. AI video generators (or “X2V” models), like Runway Gen-2, Pika 1.0 and Sora, have far more disruptive potential because they represent an entirely new way to make video.
A lot’s at stake. Christensen didn’t specify the determinants of the speed and extent of disruption, but for Hollywood it could be fast and substantial.
That’s because creator content is already disrupting Hollywood from the low end (YouTube is the most popular streaming service to TVs in the U.S., CoComelon and Mr. Beast are the most popular shows in the world in their genres), so X2V models may only throw gas on the fire; the sheer volume of creator content is overwhelming, so only infinitesimally-small percentages need to be considered competitive with Hollywood to upend the supply-demand dynamic; and the technical hurdles to consumer adoption are non-existent.
While X2V models have improved dramatically in the past year and have the potential to be disruptive, today they are not. They lack temporal consistency, motion is often janky, the output is very short, they don’t capture human emotion, they don’t offer creators fine control and you can’t sync dialog with mouths.
Sora was such a shock to the system because it solved many of these problems in one fell swoop. My layman’s reading of the technical paper is that the key innovations are the combination of transformer and diffusion models (using video “patches”), compression and ChatGPT’s nuanced understanding of language.
Sora isn’t perfect (and, importantly, not yet commercially available). But its main lesson is that video is a solvable problem. Owing to the prevalence of open source research, composability and the apparently limitless benefits of additional scale (in datasets and compute), these models will only get better.
For Hollywood, it was rightly a wakeup call. For everyone in the value chain, it’s critical to understand these tools, embrace them and figure out what will still be scarce as quality becomes abundant.
A Precise Definition of Disruption
In the last week, a lot of people have stated that Hollywood is about to be “disrupted,” but it’s important to be precise what that means.
Disruption has a colloquial meaning: radical change. It also has a more specific meaning, as outlined in Clay Christensen’s theory of disruptive innovation: disruption is the process by which new entrants target a market with a product that is initially inferior, but gets progressively better and eventually challenges the incumbents.
A lot of people are predicting that Hollywood will be “disrupted” without explaining what that means.
To say that Hollywood will be “disrupted” in the former sense is so hand wavy as to be meaningless. It’s like a weatherman saying “Big storm coming.” How big a storm? Bring-an-umbrella big, stay-off-the-roads big or board-up-the-windows-buy-sandbags-evacuate-and-expect-to-never-get-homeowners-insurance-again big? Coming tomorrow, next Tuesday, in a month or in a year?
As usual, when I use the word I mean Christensen’s more precise definition. It gives us a framework to evaluate whether and how this process might occur and the potential effects.
“X-to-Video” Models Have the Most Disruptive Potential
When discussing the potential effect of AI on Hollywood, it’s also important to be clear about what kind of AI we’re talking about. The most potentially disruptive are AI video generators, also called text-to-video (T2V), image-to-video (I2V) and video-to-video (V2V) models. I’ll refer to them as x-to-video (X2V) models, for shorthand.
Christensen distinguished between sustaining and disruptive innovations. The former enable incumbents to do things better or cheaper (the fifth blade on the razor); the latter lower entry barriers and catalyze the disruptive process (a subscription business model for mail order razor blades). Technologies are not inherently one or the other—it depends on how they are used—but some have more disruptive potential than others.
AI Used to Improve Efficiency of Existing Workflows
As I described in Is GenAI a Sustaining or Disruptive Innovation in Hollywood?, many GenAI tools are being used to improve the efficiency of existing production workflows, the definition of a sustaining innovation. For example:
Flawless uses GenAI to make cinematic quality “dubbing” that makes it look and sound like any actor can speak the local language.
VFX shop MARZ has introduced Vanity AI, among other tools, which dramatically reduces the time and cost of “digital makeup” (removing flaws and signs of aging on actors).
Cuebric uses GenAI to quickly generate the backdrops displayed on LED panels during virtual production shoots.
Adobe is embedding GenAI tools (Firefly) into its existing edit suite, Photoshop, Premiere Pro and After Effects, that will automate and speed existing processes.
It is also possible to use text-to-image (T2I) generators, like Midjourney or DALL-E, to create storyboards or other concept art a lot faster and less expensively.
Today, making premium content is very costly and labor intensive. Hundreds—and sometimes thousands—of people are needed to make TV shows or movies. Putting up a finger in the air, it’s easily conceivable that collectively these kinds of tools could eventually compress the time required to make a cinematic-quality movie by 30-50% and perhaps reduce labor needs by a similar degree. Over time, maybe even more.
X2V models have the potential to be far more disruptive because they provide an entirely new way of creating video.
X2V Models
The far more disruptive threat is X2V models, like those from Runway, Pika, Genmo (Replay), Kaiber, the yet-to-be-released Google model (Lumiere) and, of course, Sora, as well as open-source models like Stable Video Diffusion. As opposed to sustaining innovations, X2V models present an entirely new way to make video at a tiny fraction of the cost.
They entail entirely different workflows and require no actors, directors, producers, set designers, creative directors, production assistants, gaffers or key grips – just an industrious, motivated and creative person with a laptop, a small budget and perhaps some editing skills. As Runway proudly proclaims:

As a result, more so than other GenAI video applications, X2V models have the potential to dramatically reduce the barriers to create quality content and thereby blur the historical quality distinction between creator or independent content and Hollywood.
Theoretically, this disruption would look like Figure 1. The idea here is that independent content, as represented by the red YouTube line, will first appeal to the least demanding consumers, kids, then move up the performance curve to tackle the second-least demanding consumers, reality show viewers. X2V models have the potential to enable creator content to continue marching up the performance curve and challenge Hollywood for ever higher-quality content and more demanding customers.
Figure 1. A Visual Representation of the Low End Disruption of Hollywood
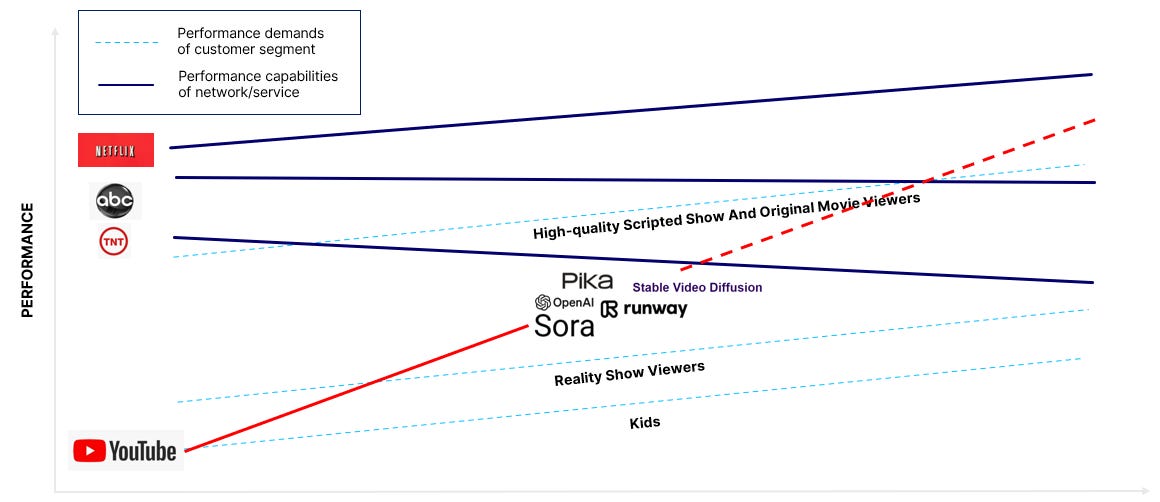
Note: YouTube is meant as a proxy for independent/creator content; TNT is a proxy for cable; ABC is a proxy for broadcast; and Netflix is, well, Netflix. Source: Author.
So far, the output of X2V models isn’t ready for primetime, literally or figuratively. The key question is: will they really produce content anyone wants to watch?
So, while theoretically they will enable creators to make higher quality stuff, so far they have not. Their output is cool, but it’s not ready for primetime, in the literal or figurative sense. Neither you nor I would plop down on the couch at 8PM and watch AI-generated video. All disruptive innovations start out as not “good enough”—that is to say, crappy—by definition. But the reverse is not necessarily true. Just because something is crappy does not mean it is destined to prove disruptive.
The key question is: will they enable content that people want to watch? Like a diffusion model de-noising an image, the release of Sora and several other recent innovations bring the answer into sharper focus.
Consumers Could Adopt AI Video Very Fast
Before getting to the implications of Sora, let’s revisit what’s at stake for Hollywood.
As I’ve written before (How Will the “Disruption” of Hollywood Play Out?), both the speed and extent of disruption can vary. Sometimes it is fast and complete (the incumbents are pushed entirely or almost entirely out of business), sometimes it is slow and partial (the incumbents cede the low end of the market, but they retain a profitable high end). In that piece, I identified a few factors that determine the extent and speed of disruption:
The ease for the new entrant(s) to move upmarket.
The ease of consumer adoption of the competing product.
The degree to which the competing product introduces new features that change the consumer definition of quality.
The degree of inertia among incumbents.
The size and persistence of the high end of the market.
The latter three are hard to address today. We don’t yet know how AI video will change consumer behavior or how consumers define quality; we don’t know how incumbents will react (although I have written before that I think they are ill-prepared, largely owing to the complex ecosystem of talent, agencies, unions, etc., in which they operate); and we don’t know how big or persistent the “high end” market of traditional, professionally-produced video will prove to be.
In the sections below, I’ll discuss what Sora tells us about the first one, the ease of AI-generated video moving upmarket.
But let’s spend a minute on the second one. Consumers could shift their viewing to AI-created or enhanced video very fast, for a few reasons: 1) the disruption of Hollywood from creator content is already underway, GenAI just throws gas on the fire; 2) the sheer volume of creator content is overwhelming; and 3) the hurdles to adoption are almost non-existent.
Low End Disruption is Already Underway
Creator content is already disrupting Hollywood from the bottom. Here’s the latest version of Nielsen’s “The Gauge,” a chart I have pasted into other essays (Figure 2). As shown, the largest streaming service on TVs in the U.S. is YouTube. (Importantly, keep in mind this excludes usage on mobile or desktop and also YouTube TV.) That means U.S. households watch more YouTube on their televisions than Hulu, Disney+, Peacock, Max and Paramount+ combined.
Americans watch more YouTube on their televisions than Hulu, Disney+, Peacock, Max and Paramount+ combined.
For years, many have argued, or perhaps wished, that YouTube was not a threat to traditional TV because it satisfied a very different use case. This data directly refutes that, because this is exactly the same use case as traditional TV: watching on a television.
Figure 2. YouTube is the Largest Streaming Service on TVs in the U.S.
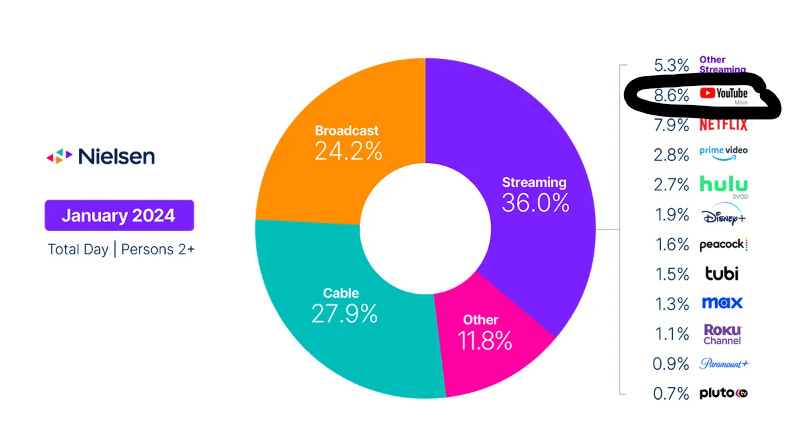
Source: Nielsen
Figure 3. The Low End Disruption of Hollywood is Already Underway

Source: Author.
Figure 3 shows a slightly modified version of the chart I showed earlier. As implied by the CoComelon and Mr. Beast logos and the dates at the bottom, even before the advent of X2V models, independent content is already marching up the performance curve and disrupting Hollywood from the bottom. CoComelon, available on both YouTube and Netflix, is probably the most popular kids show in the world by time viewed. Figure 4 shows the most-viewed shows on premium streaming services in the U.S. last year, according to Nielsen. It also shows my estimates, based on Social Blade data, of total minutes viewed of CoComelon on YouTube, both domestically and globally. Note that Bluey viewership on Disney+ domestically beats CoComelon domestically on Netflix, but adding in the CoComelon viewing on YouTube in the U.S., it is the most viewed show in the entire U.S., higher than Suits. With an estimated 80 billion minutes viewed globally last year, it is also probably the most popular kids show in the world.
Figure 4. CoComelon is the Most Popular Kids Show in the World

Source: Nielsen, Social Blade, Author estimates.
Similarly, if you consider the videos on Mr. Beast’s primary channel1 to collectively constitute “a show,” Mr. Beast2 is the most popular show in the world. Figure 5 shows the most viewed shows on Netflix globally from January-June last year, as released in Netflix’s recent “What We Watched” report. (Note that this chart combines all seasons of the most popular shows for comparability.) It also shows an estimate of Mr. Beast viewership over the same six month period, based on a 18.98 minutes average video length (from VidIQ) and an estimated 70% completion rate. As illustrated, in the first half of 2023, Mr. Beast viewership was probably close to double the most viewed series on Netflix, Ginny & Georgia.
Figure 5. Mr. Beast Was Probably the Most Popular Show in the World in 1H23

Source: What We Watched: A Netflix Engagement Report - Jan-June 2023, Social Blade, VidIQ, Tim Denning, Author estimates.
The Disruptive Power of Creator Video is Overwhelming
Sometimes an industry is disrupted by only one successful disruptor. For instance, I’d argue that the pay TV value chain was largely disrupted by one company, Netflix. In this case, there are tens of millions of disruptors: independent creators. The sheer scale of creator content is overwhelming.
If even 0.01% of YouTube content is considered competitive with Hollywood, this would represent 2X Hollywood’s annual output.
I’ve cited these numbers in other posts, but I think they’re worth repeating. I (generously) estimate that last year Hollywood produced about 15,000 hours of original TV and film. By comparison, in 2019 YouTube disclosed that creators upload 500 hours of video to the platform per minute (a number that is surely higher by now), or >250 million hours per year. If even 0.01% of this content is considered competitive with Hollywood, this would represent 30,000 hours of content, or twice Hollywood’s annual output. If 0.1% proves competitive, it is 20x.
The Hurdles to Consumer Adoption are Non-Existent
There’s nothing stopping AI video from becoming very popular, very fast. For comparison, consider what needed to happen for Netflix to disrupt pay TV. It required:
Near-ubiquitous availability of broadband.
Near-ubiquitous consumer broadband penetration (i.e., take-up).
That Netflix license or produce enough good content to compel consumers to subscribe.
Near-ubiquitous penetration of connected TVs.
A consumer behavior shift, namely that they become accustomed to streaming video to their televisions.
If there was a great scripted drama or comedy on YouTube, it could be the #1 show in the U.S. overnight.
In stark contrast, all of those conditions are now in place. As noted above (Figure 2), YouTube is already the #1 streaming service to televisions. And, as shown in Figure 6, almost 90% of U.S households pay for at least one streaming service and, as shown in Figure 7, penetration of connected TVs is approaching 90% in the U.S. If there was a great scripted drama or comedy on YouTube, it could be the #1 show in the U.S. overnight.
Figure 6. 90% of U.S. Households Have at Least 1 Streaming Subscription
Source: U.S. Census Bureau, OECD, MoffettNathanson, Parks Associates, Author estimates.
Figure 7. Connected TV Penetration is Also Near 90% in the U.S.
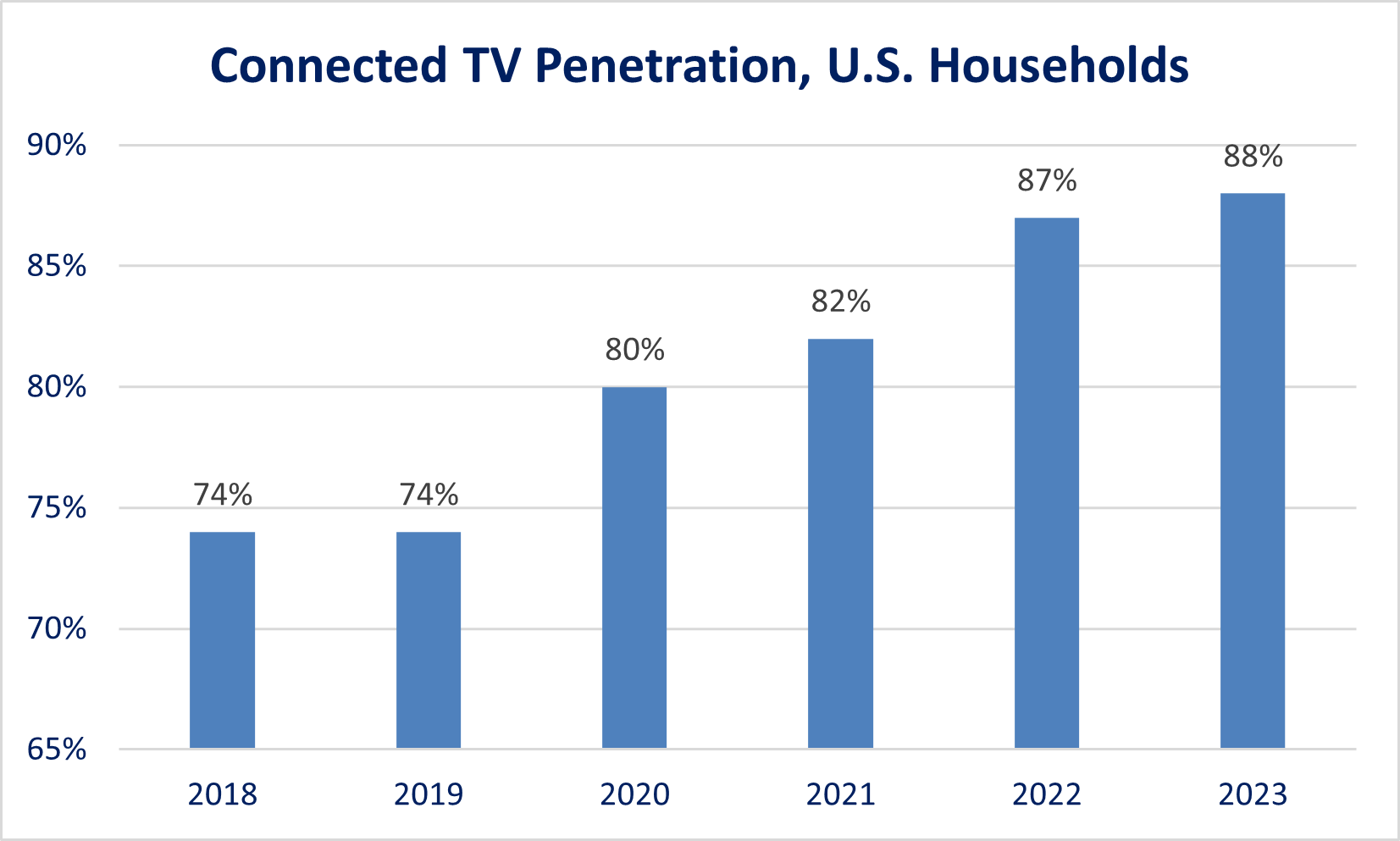
Source: Statista.
The Current State of X2V
To state the (probably) obvious, X2V models are closely related to T2I models like Midjourney and DALL-E. T2I models create one image and X2V models create multiple sequential images, which simulate motion when shown in rapid succession (the standard is 24 frames per second). You can think of X2V models as more sophisticated and far more complex versions of T2I models, or T2I models as specialized versions of X2V models, in which the output is only one frame.
So, a good place to start is with AI image generation. T2I models have been progressing at an amazing rate, as highlighted in this article about Midjourney. Here are two images, showing the improvement from V1-V6, over about a year. By V6, it is impossible to distinguish the image from a photograph.
Figure 8. Midjourney Has Made Startling Progress in a Year


Top prompt: “An attractive woman with red lips and long wavy blonde hair, dressing up in space suit, holding an ice-cream cone.” Bottom prompt: “Food magazine photo of a pizza with melted cheese, tomato and rosemary.” Source: Henrique Centieiro & Bee Lee.
Even before the advent of Sora, X2V models have also been improving at a startling rate. Consider the two videos pasted below. Pepperoni Hug Spot was created in April 2023 and The Cold Call was posted in November, seven months later, both using Runway Gen-2.
The first video is a disturbing, fever dream of a commercial. The second one is vastly better, but it still highlights some of the current limitations.
Resolution. Resolution has improved a lot—Gen-2 produces output at 1080p (1920 x 1080 pixels)—but it still falls short of cinematic-quality cameras, which shoot in 4K (3840 x 2180) or better.
Temporal consistency. Objects, people, lighting and color may vary from frame-to-frame.
Temporal coherence/real-world physics. Current commercially-available X2V models have a big problem with motion. (You can see this in The Cold Call when looking at cars move or people walk.) This includes natural looking motion of humans, animals and vehicles, and more complex interactions, like fluid dynamics.
Length. Owing to the computational intensity, challenges of maintaining consistency and demands on memory to generate multiple frames, most X2V models are limited to output of only a few seconds (three seconds for Pika 1.0 and up to 18 seconds for Runway Gen-2).
Speech and emotional range of humans. Today, none of the commercial T2V models make it possible to sync audio with mouths and fail to capture nuanced changes in expressions. (In The Cold Call, Uncanny Harry probably animated the characters’ mouths using a tool like D_ID.)
Control. T2V models have progressively been adding more creator control. For instance, late last year Runway added both Director Mode and Motion Brush to Gen-2, enabling creators to move the camera and identify specific elements in an image that should move (Figure 9). For the most part, however, in most X2V models, exerting creative control requires refining the reference image or reference video or the clumsy and costly process of iterating through multiple prompts.
Figure 9. Runway Gen-2 Product Development June-November 2023

Source: Author.
What’s So Great About Sora?
Sora was such a shock because, in one fell swoop, it addressed many (although, importantly, not all) of these limitations.
Consider just this one video. The realism and frame-to-frame consistency of the woman, the believability of motion, the 1 minute length, the reflections of light on the street and in her sunglasses are all quantum leaps over commercially-available models.
Prompt: “A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.” Source: OpenAI.
The Sora technical paper can be found here. I can’t claim to understand the whole thing, but here’s my layman’s interpretation of the primary innovations relative to other X2V models that enable such startling output:
1.) The combination of transformer and diffusion models through the use of “spacetime patches.” Sora is a diffusion transformer model. To understand this requires a high-level understanding of how both diffusion and transformer models work.
Diffusion models are the foundation of most image and video generation models. The basic idea is that the model is trained by starting with images and then progressively adding noise to the image. The model then learns to reverse this process, de-noising a noisy image to arrive at something clear and recognizable. In the case of text-to-image generators, the model must also be trained on text-image pairs, or captions.
To generate a new image, the model receives a text prompt, encodes the text so that it can understand its meaning, then it starts with a very noisy image and successively removes noise. Throughout the de-noising process, it uses the encoded text as a guide to iterate towards the relevant image.
Transformer architectures are the critical innovation underlying large language models (LLMs), such as the OpenAI GPT series, Google Gemini and open source models like Meta’s Llama series or those from Mistral. In a transformer model, the atomic unit is the “token.”
Simplistically, LLMs convert text (words, components of words or even punctuation) to tokens, then these tokens are assigned a unique multi-dimensional vector value (a process called embedding). (GPT-3, for instance, assigns 2,048 dimensions to each token, each of which is a discrete value.) Then, through the use of large scale data, they determine the semantic relationship between those tokens and assign weights based on the relative importance of each token (through what is known as an “attention mechanism”).3 Through this training process, the models refine the vector values for each token. As a crude example, the vector value of “teacher” might be close to “school” or “student” and far from “kumquat.”
While the tokens in a LLM are text, the tokens in Sora are video “spacetime patches.” First, the model cuts up the video into patches, which are components of a video frame over time (hence “spacetime”). These patches are then converted into tokens, just like a LLM, and run through a similar training process (this time, on large scale video, not large scale text). This enables the model to understand nuanced semantic relationships of patches to other patches, both in space and over time. These patches are also associated with text, through text-patch pairs.
Sora combines the concepts of diffusion and transformer models by starting with noisy patches and then running a diffusion process, guided by the text prompt, to arrive at “clean” patches. Not that it helps much, but here’s the visual representation from OpenAI (Figure 10).
This approach appears to be the key behind such smooth and life-like motion and character/object/lighting/color consistency from frame-to-frame.
Figure 10. The Visual Representation of “Spacetime Patches”

Source: OpenAI.
2.) Compression. I skipped over this part, but prior to embedding as tokens, the spacetime patches are compressed. (Probably in the same way that digital video has been compressed for decades, namely by only retaining the information that changes frame-to-frame or patch-to-patch.) The diffusion process also begins with noisy compressed patches and the final clean patches are then upscaled to produce the video.
This compression is more computationally efficient and likely one of the key reasons that the model is able to output videos of much longer duration.
3.) Leveraging GPT. OpenAI is at the forefront of natural language processing (NLP). This arguably gives it a leg up in understanding the nuances of text prompts. The paper also states that Sora uses GPT to expand on short user prompts and add detail that the prompt lacks.
This more nuanced understanding of language arguably positions Sora better to understand users’ intentions and improves the relevance of the output.
Sora Overshadowed Several Other Recent Advancements
Although Sora overshadowed everything else AI, in recent weeks there have been a rash of X2V developments from Google, ByteDance and Nvidia.
Lumiere. Last month, Google announced Lumiere, which, like Sora, isn’t yet available commercially. As you can see in the video below, it also produces far more natural motion than commercially-available X2V models. The chief breakthrough is that it creates all the keyframes (most important frames in the video) in one pass, unlike other models that generate keyframes sequentially and then fill in the frames between them. This more holistic understanding of the video enables it to portray more natural looking transitions.
Boximator. Last week, a group of researchers at ByteDance announced Boximator, a plug-in for existing video diffusion models. As shown below, Boximator gives creators the ability to identify specific video elements (by drawing boxes) and direct how they should move.
ConsiStory. Two weeks ago Nvidia announced ConsiStory, a method for maintaining character consistency across frames in Stable Diffusion Video models. The basic idea is that the model identifies the subject and through a “shared attention block”—an extension of the attention mechanisms used in transformer models—makes sure that the subject (or multiple subjects) stay consistent frame-to-frame.
Figure 11. ConsiStory Enables Character Consistency

Source: Nvidia.
Sora’s Main Lesson: Video is a Solvable Problem
Sora is not perfect. Motion can still be a little janky or even defy physics. It also isn’t available yet, we don’t know what it will cost or how long it takes to render videos. We also don’t to what degree OpenAI will enable creator control (other than the prompt itself). But, more than any other X2V model, it shows that video is a solvable problem.
More than a year ago, I explained why AI video might advance very quickly in Forget Peak TV, Here Comes Infinite TV:
For the most part, these technologies are gated by…the sophistication of algorithms, the size of datasets and compute power — all things that have the potential to progress very fast…
To repeat the comparison I made above, the disruption of video distribution required a lot of earth to be dug up, fiber laid and towers built. The advancement of AI video doesn’t need any of that.
Still, just because it could happen fast didn’t mean that it would. Until Sora, it seemed conceivable that AI video would hit some sort of technical impasse. Not all AI problems are necessarily solvable. We don’t really understand the basis of human intelligence, so maybe we’ll never achieve AGI. Maybe we’ll never have true “Level 5” self-driving because we won’t be willing to accept the (inevitably) non-zero risk that self-driving cars will sometimes kill people.
X2V just needs to be good enough for us to suspend our disbelief enough to engage with the story. Sora shows why X2V is more likely than not to surpass this threshold.
Video is not general intelligence and lives are not at risk, so both the bar and the stakes are lower. Video itself is, after all, an illusion. It is not reality; it is 24 still images per second, fooling us into thinking we’re looking at a moving image. And, for any fictional show or movie, we also know that what we’re seeing is not real. X2V just needs to be good enough for us to suspend our disbelief and engage with the story. Sora shows why X2V is more likely than not to surpass this threshold, and relatively soon, for three reasons:
Open source. AI is somewhat unusual in the sense that so much of the development is playing out in the public domain, even advancements by private companies. (For instance, the chief innovation underlying OpenAI is transformer architectures pioneered by Google.) Perhaps this is because the roots of a lot of AI research are in academia, a belief that open source serves the greater good and speeds development or the public relations benefits of being at the cutting edge. Whatever the reasons, the tendency for so much research to be released publicly is clearly speeding the pace of innovation.
Composability. Following from the prior point, while the Sora technical paper doesn’t completely give away the secret sauce on the underlying architecture and model, its numerous citations make it clear that it builds on many prior advancements. These include the concept of transformer diffusion models, spacetime patches, advancements in diffusion models and advancements in text conditioning. In software, the ability to combine numerous different tools and models, like so many Lego blocks, is called composability. A lot of AI models are designed to be modular, so that they can be easily combined or used with other tools. This too speeds the pace of innovation.
Figure 12. Scale Improves Model Performance
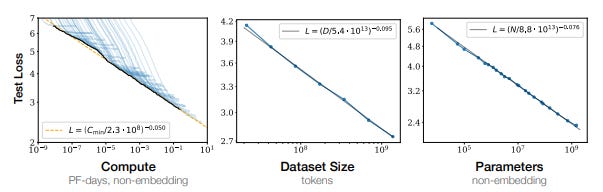
Source: Scaling Laws for Neural Language Models.
Scale. In 2020, researchers at OpenAI published a paper called Scaling Laws for Neural Language Models, which found that scale was more important than the architecture of the model. The research showed that LLM performance improves smoothly with increases in the size of the training dataset, the number of parameters (a measure of model complexity) and compute. As shown in Figure 12, there is an apparently unbounded inverse power law relationship between the scale of each variable and model error. In other words, there is no clear upper limit to the benefits of scale. This can be seen vividly in videos that accompany the paper. Figure 13 shows three videos of a dog wearing a blue hat and playing in the snow at different levels of compute.
Figure 13. Model Improvement as Compute Scales
Top video at “Base” compute, middle video at 4x compute and bottom video at 32x compute. Source: OpenAI.
These three factors—open source development, composability and ever-increasing scale of datasets and compute—show why X2V is only going to get better.
The Holy Sh*t Moment
From all the press over the last week, it’s clear that Sora was rightly a big wake up call for a lot of people. Perhaps the most vivid example was Tyler Perry’s decision to halt expansion of his production facilities.
What was theoretical a year ago is becoming more tangible by the week. These tools will probably only keep getting better and, as a result, the volume of “quality” content will likely increase dramatically in coming years. The challenge for everyone in the value chain is the same: 1) embrace these tools; 2) determine how they help you do your job better; and 2) figure out what becomes scarce as quality approaches infinite, something I wrote about most recently here.
Mr. Beast runs several other YouTube channels, including Mr. Beast 2, Mr. Beast 3, Mr. Beast Gaming and Beast Reacts.
When italicized, Mr. Beast represents the collective videos posted to Mr. Beast’s primary channel.
The importance of attention mechanisms is why the seminal paper from Google Deepmind that first proposed transformer architectures was titled Attention is All You Need.
This is the first good ai Substack Ive found on here
Awesome piece! Minor edit: Pika can generate videos up to 15sec (not 3), 3sec is the length of the initial generation which you can extend. Runway works pretty much the same way, 18sec is the max. duration, the initial length is 4sec.